The Curious Mind #1: What’s even AI? Where Did It All Start?
The Curious Mind #1: What’s even AI? Where Did It All Start?
Overview of Post
Everyone says AI is everywhere. But what is it really? A brain for machines, a calculator on steroids, or just a buzzword that stuck around for too long? To answer that, let’s go back to the brain, and then walk through how machines tried to mimic it.
The Brain’s Way of Solving Problems
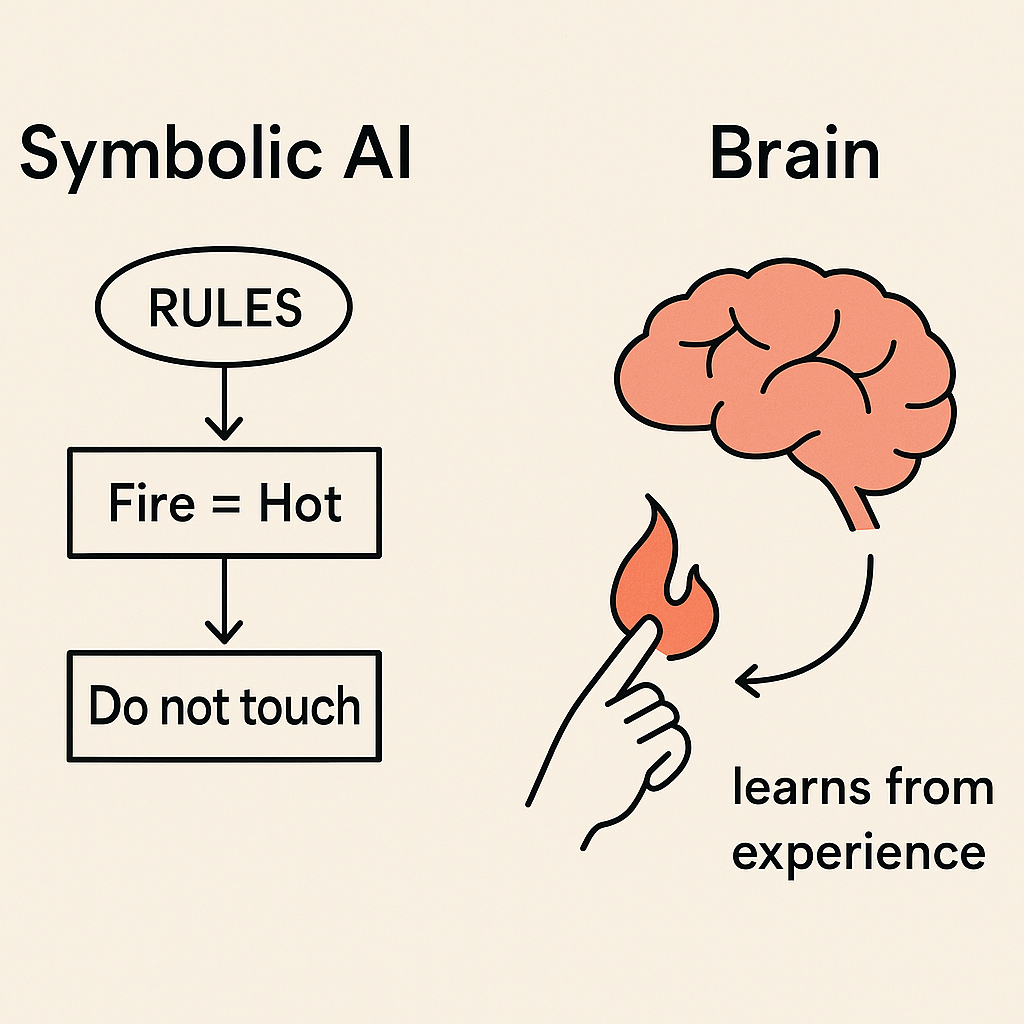
Your brain is a prediction engine. When you touch fire as a child, your neurons wire together to remember pain. When you see a dog, your brain does not check a rulebook. Instead, millions of neurons fire in patterns that encode your past experiences of “dogness.”
This is intelligence: the ability to generalize from experience. Machines wanted to do the same. The first attempt was not to build neurons but to write rules. If fire = hot, do not touch. If dog = four legs, tail, barks, then classify as dog. This was called symbolic AI, a world of handcrafted logic.
It worked for narrow problems but collapsed the moment reality got messy. The brain thrives in messy situations, rules do not.
In the summer of 1956, John McCarthy, Marvin Minsky, Claude Shannon, and Nathaniel Rochester gathered at Dartmouth College for the Dartmouth Summer Research Project on AI.
It was here that the term “Artificial Intelligence” was first coined. The proposal stated:
“Every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.”
This wasn’t a coding hackathon. It was a blueprint for a field, pointing to neural nets, search, symbolic reasoning, and language. The dream was set.
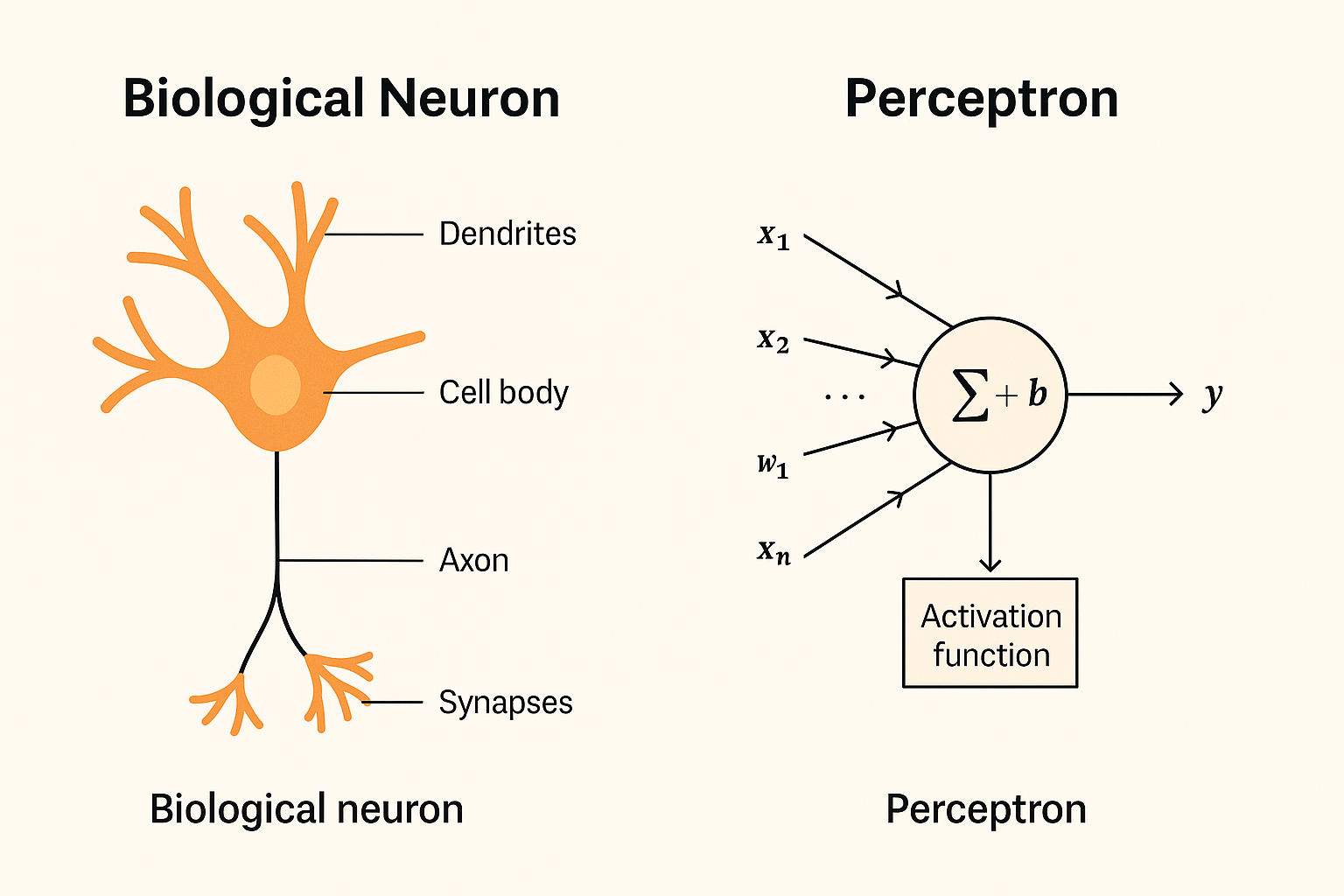
In 1957, Frank Rosenblatt asked: what if machines could learn like neurons? He introduced the perceptron, the first mathematical model of a neuron.
The perceptron takes inputs, multiplies them by weights, adds a bias, and runs them through a step function:
f(x) = h(w ⋅ x + b)
Inputs (xi) = features, like pixel values
Weights (wi) = importance of each feature
Bias (b) = adjusts the decision boundary
Step function (h) = binary output (1 or 0)
This made the perceptron a linear classifier, able to draw a straight-line boundary between classes.
Rosenblatt also built hardware: the Mark I Perceptron (1960). It had a 20×20 grid of photocells acting like a retina, connected randomly to association units, with adjustable weights implemented by potentiometers. Motors updated these weights during learning.
It was able to classify simple patterns and created massive excitement. The New York Times even claimed it could one day walk, talk, and be conscious ( NYT Archive, 1958).
But it had limits: it could not solve problems like XOR, which are not linearly separable.
In parallel, a very different idea was brewing. Could machines predict text instead of reasoning with logic?
Claude Shannon (1948–1951): Measured the entropy of English by asking humans to guess the next letter. This proved language is statistically predictable.
N-grams (1960s–1970s): Instead of full reasoning, approximate by looking at the last few words. A trigram model predicts P(wt | wt−2, wt−1).
Corpora: The Brown Corpus (1961) provided 1M words of text, enabling statistical models to be tested.
Applications: Early speech recognition experiments at IBM and Bell Labs in the 1970s used n-gram models with smoothing methods like Good-Turing and later Kneser-Ney.
This is important because modern LLMs still use the same objective: predict the next token. The difference is scale and neural architectures, not the goal.
After Dartmouth and Perceptron, the early years were dominated by symbolic AI. Researchers built expert systems: programs that encoded domain-specific knowledge as logical rules.
Example: MYCIN (1972) at Stanford. It used ~600 rules to recommend antibiotics for infections. In narrow cases, it performed as well as doctors.
But symbolic AI faced the knowledge acquisition bottleneck. Writing and maintaining rules for messy, real-world domains became impossible. This started the search for an alternative in different ways.
Prolog: Programming in Logic
In 1972, Alain Colmerauer and Philippe Roussel introduced Prolog (“Programming in Logic”). Unlike imperative programming, Prolog was declarative. You wrote facts and rules, and the system inferred answers.
Example:
cat(tom).
mouse(jerry).
hunts(X, Y) :- cat(X), mouse(Y).
Query: ?- hunts(tom, jerry). → true
Prolog fueled symbolic AI and was central to Japan’s Fifth Generation Computer Project (1982–1992), which invested $400M in building intelligent reasoning machines.
Machine Learning: Data Becomes the Teacher
📖 Further reading: Statistical Learning Theory – Vapnik, Foundations of Machine Learning – Mohri, Rostamizadeh, Talwalkar
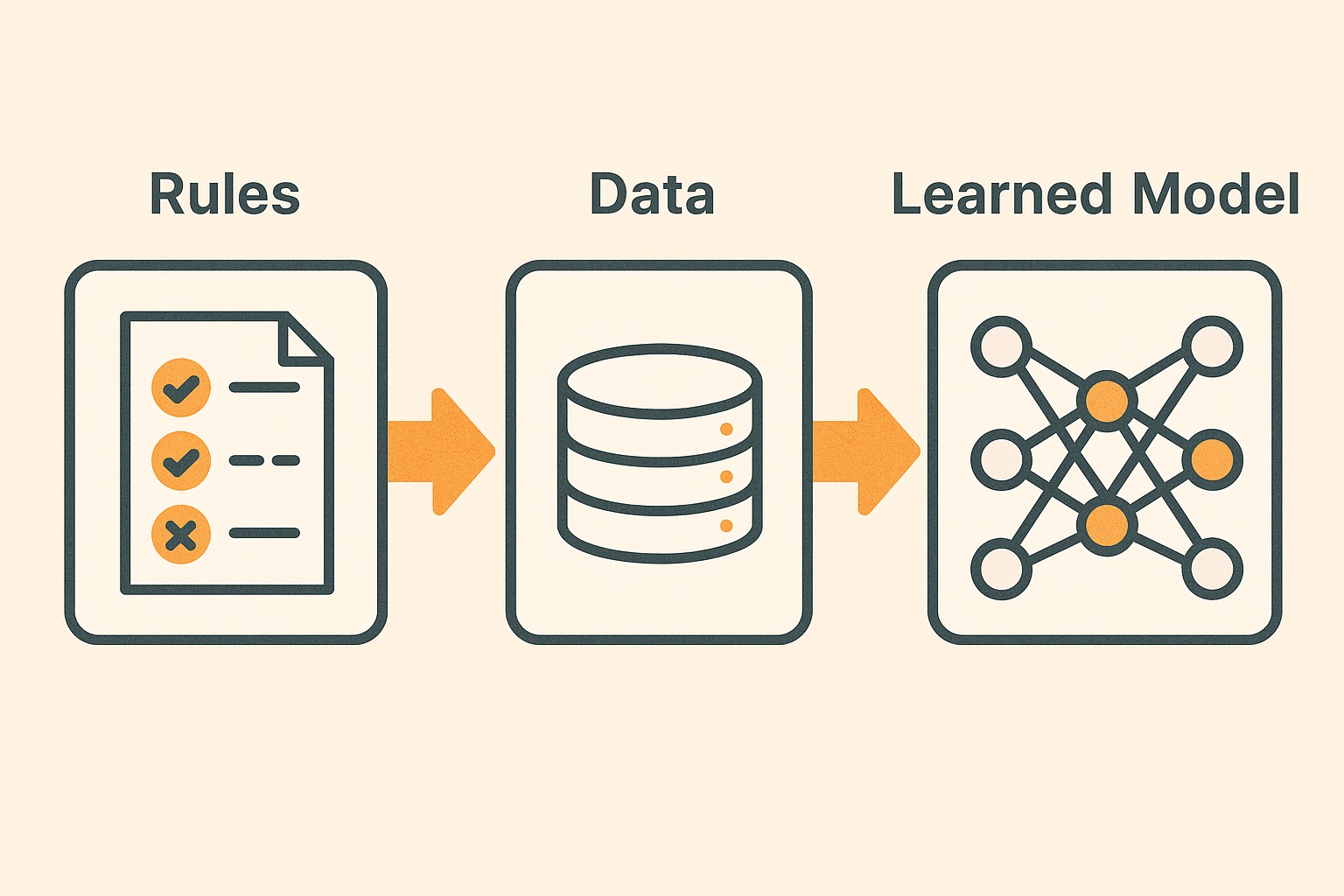
By the 1980s, symbolic AI was stuck. Rules could not capture the endless messiness of the real world. The new idea was radical: instead of writing rules by hand, feed the system data and let the algorithm discover the rules on its own.
This marked the birth of machine learning. The transition was not just philosophical but deeply mathematical. Vladimir Vapnik and Alexey Chervonenkis formalized the idea through Statistical Learning Theory.
The central problem was generalization: given a finite set of training data, how can a model make accurate predictions on unseen cases? Vapnik and Chervonenkis introduced key ideas:
VC Dimension: a measure of the capacity of a model class
Empirical Risk Minimization (ERM): minimize training error
Structural Risk Minimization (SRM): balance training error with model complexity to avoid overfitting
This made machine learning a science instead of guesswork.
Early Algorithms: Trees, Bayes, and Margins
Once the theory was in place, practical algorithms began to shape industries.
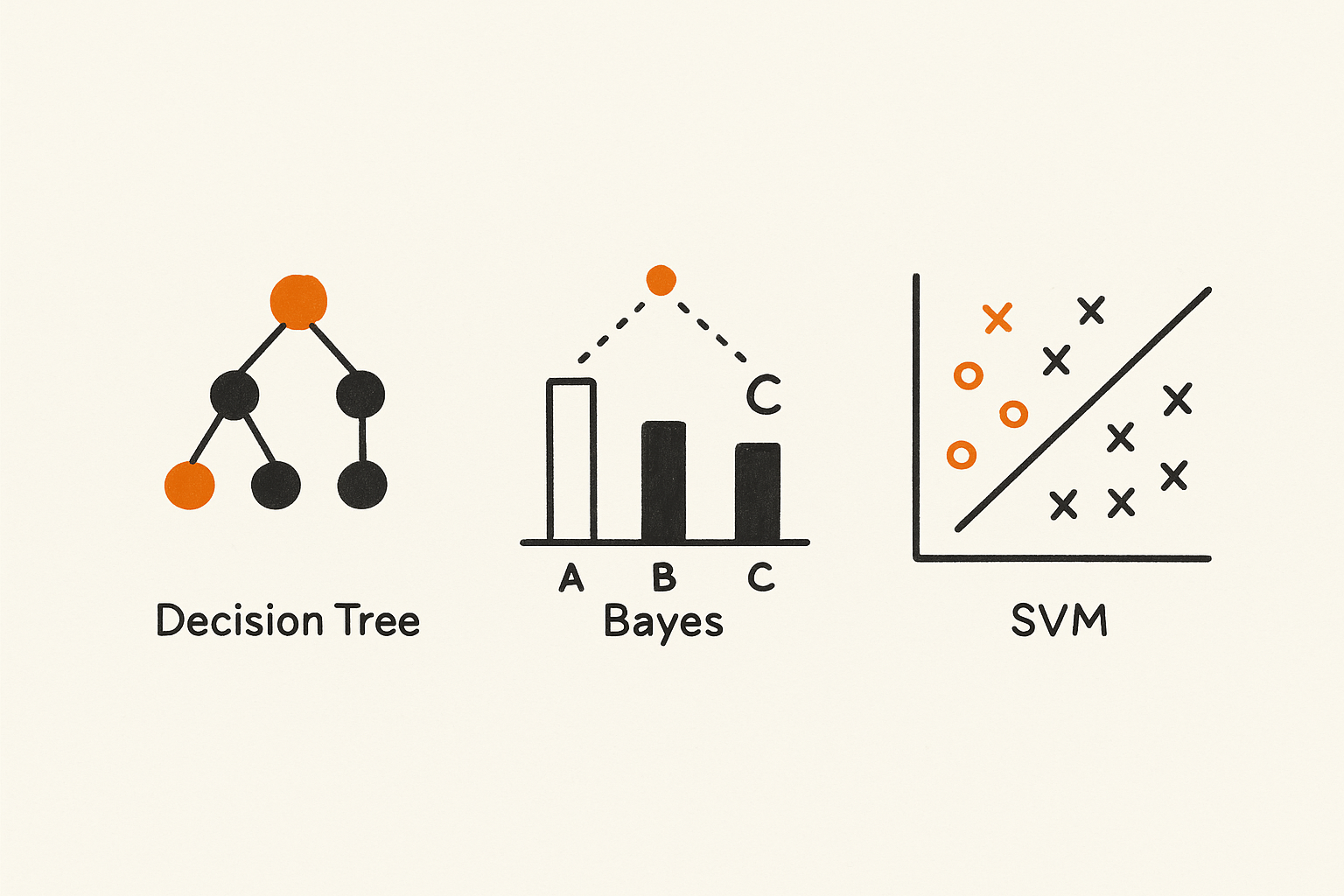
Decision Trees Ross Quinlan introduced ID3 in 1986. Decision trees split data step by step, creating if-then rules directly from examples. They were interpretable and useful in fraud detection, medical diagnosis, and customer segmentation.
Naive Bayes Rooted in Bayes’ theorem, Naive Bayes assumes features are independent. Despite this simplification, it worked well for text classification. In the 1990s, it powered spam filters and document classification at scale.
Support Vector Machines (SVMs) Introduced by Vapnik in the 1990s, SVMs aimed to find the hyperplane that best separated classes by maximizing the margin. They excelled in handwriting recognition, face detection, and bioinformatics, showing strong generalization power in high-dimensional spaces.
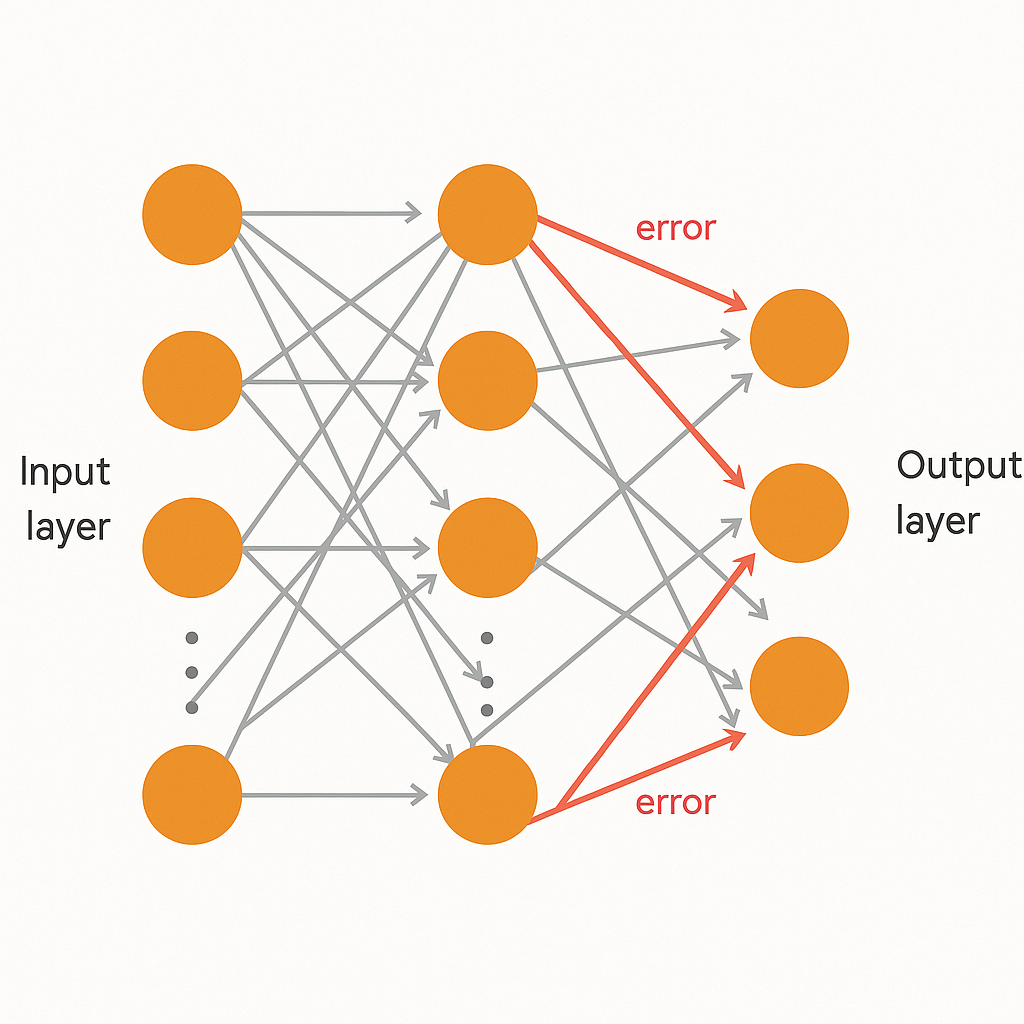
The human brain builds understanding in layers: from edges to shapes to objects. A single perceptron could not do that, but multilayer perceptrons (MLPs) could.
In 1986, Rumelhart, Hinton, and Williams popularized backpropagation, a method to train these multilayer networks. Errors from the output layer were propagated backward, adjusting weights in earlier layers step by step.
Backpropagation used gradient descent, nudging weights toward values that reduced error. This made MLPs powerful enough to approximate almost any function, a fact later proven by the Universal Approximation Theorem.
While limited by the compute power and small datasets of the time, backprop laid the foundation for the neural networks that would later dominate AI.
By the 1990s, AI stood on two strong legs. On one side, machine learning algorithms like decision trees, Naive Bayes, and SVMs were powering applications in finance, healthcare, and telecom. On the other side, neural networks with backpropagation had the theoretical power to approximate almost anything, but they were held back by the limits of data and compute.
Running alongside these was a quieter but equally important thread in language modeling. From Claude Shannon’s early experiments with predictability in English text to n-gram models and speech recognition research, the idea of predicting the next word became a practical way to capture patterns in language.
When large datasets appeared in the 2000s and GPUs unlocked scale, these three currents began to converge. Data driven algorithms, neural networks with backpropagation, and the tradition of next word prediction merged into what we now call deep learning.
The perceptron’s humble beginnings, the rigor of statistical learning theory, the breakthrough of backpropagation, and the persistence of language modeling all came together to create the foundations of modern AI.
In the next blog, we will explore how neural networks evolved into CNNs, RNNs, and deep learning, and how the need for compute and data bottlenecks set the stage for the birth of transformers.